

How does this AI thing even work
The maths behind the machine and why it loves to lie

What do you mean by AI?
AI is often used as a catch-all term. In reality, “artificial intelligence” can refer to anything from a simple pattern-matching program to a sophisticated learning system. AI is just an umbrella term for a wide range of slightly similar things.
ChatGPT has little in common with software a bank might use to evaluate loans, they work fundamentally differently, are used for different purposes, and fail in different ways.
Compounding this, “AI-enabled” everything has become a marketing trope. Companies eagerly slapping the AI label on everything from refrigerators to grills, to pillows, mirrors, you name it. At CES last year, exhibitors touted an AI pillow that adjusts to reduce snoring, an app that uses AI to “translate” your baby’s cries, a cat door using AI vision to stop kitty from bringing in dead mice, and even a grill claiming to use AI for perfectly cooked steak. These examples range from genuinely innovative to completely absurd.
So, in summary, it isn’t some magic and isn’t one single thing. It’s a broad field of technologies, and calling something “AI” doesn’t tell you much until you dig into what’s actually going on under the hood.
The most prominent AI technology right now is generative AI. Generative AI is being applied everywhere from AI chatbots to image generators, voice synthesis, email writing, and so on. In fact most news articles you read these days are at least partially AI generated summaries of AP1 news stories. Generative AI has exploded onto the scene and is demonstrating some amazing, disturbing and fascinating results across many, many industries.
I’ll leave the debates about ethics, morality, politics and the like to a future article, as today I thought it’d be beneficial to try to demystify the technology a bit. Edmund Burke said,
“When you fear something, learn as much about it as you can. Knowledge conquers fear”.
I do think that’s true for everything in life.
So, what is generative AI then?
Generative AI generally runs on a technology called a GPT (Generative Pretrained Transformer). And it’s this technology that runs the world’s LLMs (Large Language Models), which I’ll focus on in this article. Other GPT models for images, video, music, and the like work much in the same way; but are a little more esoteric to understand.
So, in short, the large language models are built on a neural network architecture called a Transformer, which to an 80’s kid like me is quite amusing.
Autobots Assemble!

So, these Transformers are Pretrained, which is a process of ingesting information, being prompted for responses and using positive reinforcement, tuning the model to give desirable responses. The scale of the training these days is mind-blowing, the latest models have basically ingested the text of the entire internet and are now greedily swallowing up all the videos on YouTube (through AI transcription of course) as well as, controversially, the copyright works of all the world’s authors, musicians, actors, researchers and the like.
These Transformers are Generative, in that they take some input; run it through a process and generate a novel output.
Ok, but how does something like ChatGPT actually work?
I’ve been reading into this, watching videos, reading research papers, articles and what not. It’s a heck of a lot of complex vector maths, but I think my lizard brain has absorbed enough to try to explain it.
At its core, all ChatGPT is trying to do is predict the next word (token), based on all of its training and based on what you’ve fed it as a prompt.
In order for the model to give you a good response, along with your text prompt, an internal prompt (the system prompt) is fed in at the same time with a bunch of information and rules. It’ll read something along the lines of: “you’re a large language model called ChatGPT, your job is to predict what a helpful AI assistant would say in response to the user’s input…”. It’ll outline what the model can and can’t talk about, how answers should be structured, the tone of the answer and so forth.
Then it’ll feed all of that into the process.
The process goes like this:

Tokenisation
Very simply, during the training process the model took all the words it ingested and assigned them an ID. Complex words or uncommon words might be split into pieces by the model, for ‘reasons’. For simplicity, we’ll say this makes them easier to deal with down the line.
Embedding
Each token is then converted into a vector (a list of numbers). This is called an embedding, and basically, it’s a way for the model to represent that token as a co-ordinate in a high-dimensional space. I like to break it down into fundamentals, so think of a graph with an x axis going vertically and a y axis horizontally. The embedding has been assigned a value which will put it on this vector in that graph:
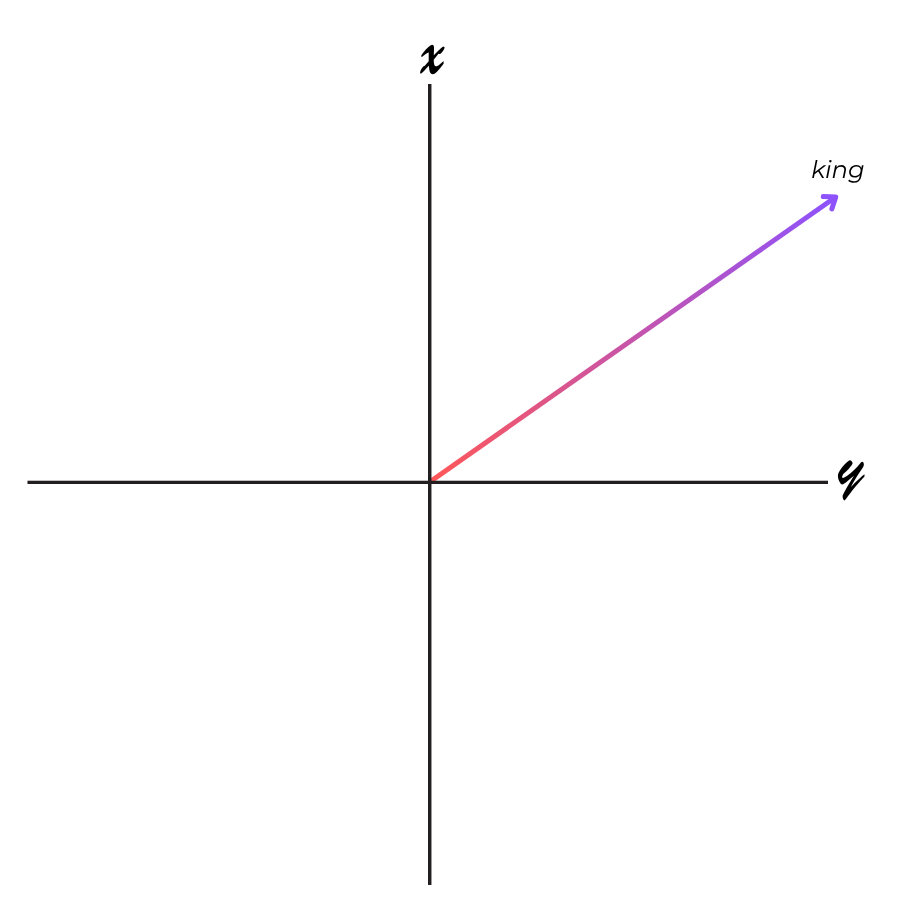
This is that word’s position in the model. Now to complexify it again; those vectors aren’t represented in two dimensions, as I’ve done above, or even three dimensions; models these days have many, many thousands of dimensions or more.
Words with similar meanings end up with vectors that point in similar directions in the dimensional model. So, imagine if you will, that we have a vector for the word ‘king’ and calculate the difference to the vector for the word ‘queen’ (we call this the dot product); this effectively represents the distance and direction between those two embeddings in the model. Now if we take the vector for the word ‘man’, and add that dot product from above, we’ll end up in the vicinity of the word ‘woman’.

Hopefully that oversimplification helps understanding how words end up in multidimensional vectors in the semantic space of the model and how words have relationships represented mathematically.
Attention
This is where the “magic” happens. Obviously, language is full of nuance, subtlety and context. So, when I look at word, it can have many different meanings both formally and informally as slang, based on the wider context. So, if I said to an LLM, “I’m going to the Big Apple next week, tell me where I should eat.”; without strong contextual understanding it’d be quite confused and likely to tell me to not eat the pips because they can be toxic.
So, the attention mechanism allows the Transformer to take your whole prompt and focus the wider context as it deals with those embeddings. If you remember from the step before; what the model now has is basically a string of numbers, each representing the vector of an embedding.
Rather than reading a sentence word by word blindly, the model can look back (or even ahead, in some cases) at other words and decide which ones are important for the task at hand. In effect, for each word being generated, the model weighs the relevance of all other words in the input (and the part of output generated so far).
Think of attention as the model’s way of deciding “what should I pay attention to?” when choosing the next word. So, from my example, “I’m going to the Big Apple next week, tell me where I should eat.”, the model should attend to the phrase “Big Apple” heavily to realize that the Big Apple refers to New York.
When you look at the maths, the attention steps are taking the vector values and multiplying them by weights based on the other embeddings in a sequence, to build context.
Layers of processing
Depending on the model in play and the papers you’re reading, the next step in the model is called a Multi-layer Perceptron or an Attention Head. What this layer of the model does is processes each vector output from the attention above, to build more context for that vector. It’ll do this in parallel for all the vectors in the sequence.
You could think of this step as a little bit like asking a long list of questions about each vector, such as “is it an English word” or “is it a noun” or “is it a number” or “is it code” and so on.
It’ll then pass the updated vectors to another attention layer to be multiplied by all the other vectors in the sequence again, building even more context, before going through the next Attention Head.
As the data passes through these layers, the model builds up more complex features. Some Attention Heads might be tracking grammar, others factual associations etc. So, as it progresses through these layers the vectors get more and more “meaning”. Modern modes have dozens of these layers as well as some normalisation layers and ome other bits that aren’t relevant here.
I’ll pause here to remind you, there’s no intelligence happening here. All the model is doing is multiplying those vector values together based on weights in the model (from its training) and based on the information that it’s getting at each Attention Head.
Decoding
Finally, after going through all those layers of context building the, model uses this processed information to predict a probability distribution for the next token (or word). Again, just a vector math calculation based on the final value of the final vector in the sequence.
Essentially it asks: “Given everything I’ve processed so far, what is the most likely next word?”. It then multiplies the probability distribution by a small error factor, to give more variability and creativeness in its responses.
In my example above, it might predict the next token to be the word ‘That’s’. It’ll append that to your prompt and run the whole thing through the process from tokenisation, through to decoding and get a prediction for the next word. It’ll do that repeatedly until it determines that the response is complete. This is actually what ChatGPT gave me when I asked it this question:
That’s great, Carl — New York City has one of the most diverse and exciting food scenes in the world. Here's a curated list of places worth checking out, split by category to suit different moods or occasions.
It then proceeded with a curated list of restaurants that suit my tastes (I’m a vegetarian and like fine dining).
So probably worth noting then, that the newest models like ChatGPT aren’t just feeding in your prompt for context, they’re including a bunch of other information which could be, documents you’ve attached or information it’s committed to its internal memory which it built during its other chats with you.
The new models are able to take enormous prompts. Just a few years ago ChatGPT would only take a couple of paragraphs before the model lost context and effectively started “forgetting” the beginning of the prompt. These days, models are taking upwards of a million tokens, which is 4 or 5 Stephen King novels’ worth. (you might find you run out of model context much quicker if you’re on a free version of your preferred LLM).
In summary, an LLM turns your words into tokens, turns tokens into numerical embeddings (its way of “perceiving” language), then uses layers of attention-powered processing to figure out what comes next, one step at a time. It’s like a very sophisticated auto-complete that — thanks to training on massive data — “knows” how language flows and can produce results that often sound knowledgeable and coherent.
These models feel magical because they can produce text that reads as if a human wrote it. But they are not doing reasoning or understanding in a human way – there’s no intent or self-awareness. They predict text based on learned patterns. For instance, if during training, the model saw many examples of Q&A where a question starts “Why...?” and the answer often begins “Because...”, it learns that pattern. When you ask, “Why is the sky blue?”, it has seen text about Rayleigh scattering and atmospheric particles and will assemble a plausible answer drawing on that training data. The impressive part is the generalization: it wasn’t explicitly programmed with rules for every question; it learned a broad statistical picture of language and world facts, which it can apply to new queries.
Also, generative models can create things they’ve never seen word-for-word. They might recombine ideas, or phrase things in a novel way – that’s part of why it’s called “generative” and not just “repetitive.” This generative ability is double-edged: it allows creativity, but as we’ll see next, it also means the model can generate wrong information that sounds perfectly confident.
Why LLMs hallucinate
Anyone who has used AI chatbots or other generative AI has likely encountered a startling phenomenon: AI makes things up. In AI lingo, these false yet confident outputs are called “hallucinations.”
If you think back to the the math-based prediction above, you can start to see why hallucinations might happen. In short, LLMs hallucinate because they lack a built-in sense of truth or reality. They only know statistical patterns in language.
LLMs are trained with re-enforcement training, i.e. they’re “rewarded” for giving good responses, and researchers try to tune bad responses out of them. However, they’re not given any reward for not responding at all, and thus there’s an inherent drive to always give some response.
If you ask about an obscure topic that wasn’t well-covered in the model’s training data, the AI may “fill in the blanks” with something plausible sounding. It doesn’t want to say, “I don’t know” (unless specifically trained to), so it fabricates an answer based on whatever related info it can infer.
How to minimise hallucinations
The more context a prompt has the more likely a model is to end up with the correct embeddings and have attention calculate the best vectors to give you a better-quality answer. So, the more information you provide in your prompt and related attachments the more likely the model is to find similar information from its training data and give you better results. I always tell people to stop using ChatGPT like a search engine and trying to give it a few relevant key words; what you want to be is as explanatory and verbose as possible, to glean the best results.
The next suggestion is to switch the model to web search mode or use a model that searches the web. That way, you’re relying on the model’s training to understand your question and go online and read relevant material to find answers that look relevant. It’ll then give you those results nicely summarised along with links to the sites, so you can cross check yourself.
You can take that to the next level if you’re on the paid plan of ChatGPT, using its deep research mode to go and research a topic for you. It’ll take it around ten minutes to come back with a detailed research paper with cited sources for the topic of your choice. It’ll also ask a number of relevant questions of you beforehand, to make the research as relevant as possible.
How are AI developers reducing hallucinations in their models?
Developers are developing a whole new class of generative models and are focusing on a greater degree of specificity for models. Meaning they can be tuned to specific use cases, rather than being generalists. One good example of this is called RAG (Retrieval-Augmented Generation). This is where a model will be given access to a database of relevant information, and the model is trained to get answers from that body of knowledge only. If it doesn’t find an answer, it’ll simply respond with “I cannot find the answer in the data”.
Also, on the topic of reducing model scope is the curation of training data and improving the quality of training data. So instead of training a model on all the information available online (with all the garbage therein), they’ll train it on a smaller dataset of well curated known accurate information.
There are also new methods of reinforcement learning and human feedback loops that ask humans to pick a preferred response, humans generally preferring accurate information. (you might have been asked by your favourite model to rate two responses, that’s what that’s for).
Developers are also adding post-processing guardrails to models. Effectively, fact-checking modules that assess a model’s response and send it back if it’s not correct or hallucinated.
It’s early days yet, and things are moving fast. So, as always, use AI with caution; it’s still perfectly capable of being as confidently wrong as I am on a bad day.
So, I’m sure you’ll see that in future, we’ll likely have more, smaller models which are purpose built to fill specific needs. Many organisations are building protocols to enable Agentic AI to talk to other Agentic AI for this purpose. Google recently donated their a2a (agent to agent) protocol to the Linux foundation for everyone to use. Anthropic has developed the open source MCP (Model Context Protocol) to standardise the way AI models connect to external systems and tools. I’m sure I’ll be writing an article shortly about the connected future of agentic AI.
Conclusion
With some background and detail, I hope I’ve done a little to improve your understanding of how all this works under the hood. Making it a little less mysterious will probably make AI either more or less scary depending on your view of high dimensional vector mathematics.
I know I didn’t explain anything about neural networks, and I glossed over and oversimplified many other details. I’ll perhaps go a bit deeper into those points in future.
I was going to switch gears and explain why, although the technology is well understood. Even AI researchers don’t fully understand what’s happening inside these models at a detailed level. However, this is already over 3000 words long; I’ll wrap it here and encourage you to come back for my next instalment “The Mystery in the Machine”